2026年4月9日|从工具到队友:麻醉AI助手核心原理深度拆解
一、基础信息配置

文章标题:2026年4月9日 从“代码补全”到“自主编程”:麻醉AI助手核心技术原理深度拆解
目标读者:技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师

文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点,兼顾易懂性与实用性
写作风格:条理清晰、由浅入深、语言通俗、重点突出,少晦涩理论,多对比与示例
核心目标:让读者理解概念、理清逻辑、看懂示例、记住考点,建立完整知识链路
在2026年的技术版图中,麻醉AI助手(这里用了一个生动的比喻——AI编程助手就像手术室里的麻醉AI助手一样,在开发者编码时提供精准“麻醉”级别的辅助)已经成为开发者工具箱中不可或缺的核心组件。然而很多学习者的真实困境是:会用、但不懂原理,面试被问到“AI代码助手底层是怎么工作的”就卡壳了。本文将用极简代码示例+原理图解,带你从传统方式到AI Agent模式,一步步拆解AI编程助手的核心逻辑。
二、痛点切入:为什么需要AI编程助手?
先来看传统方式下,开发一个简单的用户登录验证函数:
传统方式:开发者手写每一个细节 def validate_user_input(username, password): 手动检查用户名非空 if not username or len(username.strip()) == 0: return False, "用户名不能为空" 手动检查密码长度 if len(password) < 8: return False, "密码长度至少8位" 手动检查是否包含数字 if not any(char.isdigit() for char in password): return False, "密码必须包含数字" 手动检查是否包含字母 if not any(char.isalpha() for char in password): return False, "密码必须包含字母" 业务逻辑... return True, "验证通过"
这段代码的痛点很直观:
重复劳动:每个项目都要重写类似的校验逻辑
维护成本高:校验规则变更时需要逐一手动修改
易出纰漏:开发者容易遗漏边界条件
缺乏上下文感知:传统IDE补全只能做语法提示,不知道“用户注册模块需要什么样的校验规则”
这种“手写一切”的模式,在大规模、快节奏的开发中已难以满足效率和质量的双重要求。AI编程助手的出现,正是为了解决这一问题——它不是替代开发者,而是成为开发者的“智能搭档”,让开发者从重复劳动中解放出来,专注于更有价值的核心业务。
三、核心概念讲解:大语言模型(LLM)
定义
大语言模型(Large Language Model,LLM) 是一种基于深度学习、在海量文本数据上训练而成的神经网络模型,能够理解自然语言输入并生成连贯的文本输出。当前主流的LLM参数规模已从数十亿拓展至千亿甚至万亿级别。
拆解关键词
“大” :参数规模巨大,意味着模型的“知识容量”远超任何个人开发者
“语言” :不仅能“看懂”代码,还能“理解”注释、文档和自然语言指令
“模型” :它是一个统计模型,核心能力是根据上文预测下一个最可能出现的Token
生活化类比
可以把LLM想象成一个“读了图书馆所有编程书籍”的实习生:
你给它一个需求,它能给出实现思路
你给它一段代码,它能告诉你这段代码在做什么
但它的回答完全基于“见过的知识”,不具备真正的推理能力,所以有时会“一本正经地胡说八道”
作用与价值
在AI编程助手中,LLM负责:
理解意图:将自然语言描述转化为可执行的代码逻辑
代码生成:根据上下文预测并生成后续代码
代码解释:帮助理解陌生代码段的含义
错误诊断:分析报错信息并给出修复建议
四、关联概念讲解:AI智能体(AI Agent)
定义
AI智能体(AI Agent) 是一种能够感知环境、自主决策并采取行动来实现目标的软件实体。与传统AI问答模式不同,Agent不仅可以回答问题,还可以调用工具、执行操作、自主规划多步任务-。
它与LLM的关系
| 维度 | LLM | AI Agent |
|---|---|---|
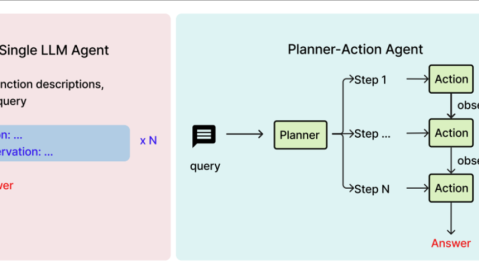
| 角色定位 | 大脑(认知核心) | 大脑+手+眼(感知+决策+行动) |
| 能力边界 | 理解和生成文本 | 理解+规划+执行+反馈循环 |
| 输入输出 | 文本→文本 | 文本/环境状态→动作/决策 |
| 典型任务 | 回答“这个函数做什么” | 执行“重构整个模块并跑通测试” |
核心特征
AI Agent通过以下能力实现自主性:
工具调用(Tool Use) :可以调用外部API、执行Shell命令、操作数据库等
多步规划(Planning) :将一个复杂任务拆解成多个子任务,按序执行
记忆机制(Memory) :包括短期记忆(当前会话上下文)和长期记忆(跨会话的项目信息)
自我反思(Self-Reflection) :执行后评估结果,必要时调整策略
五、概念关系与区别总结
一句话概括:LLM是Agent的大脑,Agent是LLM的“外挂身体”——让大模型从“只会聊”变成“能干实事”。
在AI编程助手的上下文中:
LLM 负责“思考”:理解需求、设计算法、生成代码方案
Agent 负责“行动”:读取文件、执行代码、运行测试、修复错误
一个简单对比:GitHub Copilot早期版本主要依赖LLM做代码补全(纯大脑模式);而Cursor 2.0引入的Agent模式,可以让AI自主打开文件、代码、编写函数、运行测试,实现8个AI Agent并行工作-。这就是从“大脑”到“完整智能体”的进化。
六、代码/流程示例演示
来看一个对比示例,展示传统vs AI Agent方式实现同一个任务。
任务:为项目中的所有Python文件添加标准的文件头注释
传统方式:
import os 手动遍历项目目录 project_path = "./my_project" file_header = ' Copyright 2026 ...\n Licensed under MIT\n' for root, dirs, files in os.walk(project_path): for file in files: if file.endswith('.py'): file_path = os.path.join(root, file) with open(file_path, 'r') as f: content = f.read() 如果已有文件头则跳过 if content.startswith(' Copyright'): continue with open(file_path, 'w') as f: f.write(file_header + content) print(f"已处理: {file_path}")
这段脚本约15行代码,需要开发者:
手动处理路径遍历
考虑边界条件(如文件头已存在)
处理文件读写异常
AI Agent方式(以Cursor 2.0 Agent模式为例) :
在Cursor中输入自然语言指令: "为项目中所有Python文件添加标准的MIT License文件头,如果已有文件头则跳过" Agent自动执行: 1. 扫描项目结构 → 2. 识别.py文件 → 3. 逐文件添加文件头 4. 自动处理文件写入冲突 → 5. 汇报完成状态
关键差异:
| 维度 | 传统方式 | AI Agent方式 |
|---|---|---|
| 代码量 | 15+行,需手动调试 | 1行自然语言 |
| 维护成本 | 逻辑变更需改代码 | 重新描述需求即可 |
| 边界处理 | 需开发者自己考虑 | Agent内置常见边界处理 |
| 异常恢复 | 需写try-catch | Agent自动重试/报错 |
执行流程拆解(以Claude Code为例):
用户输入:自然语言描述任务需求
LLM理解:将需求解析为任务目标和约束条件
Agent规划:拆解为多个步骤(扫描→识别→处理→验证)
工具调用:依次调用文件读取、内容修改、文件写入等操作
结果反馈:将执行结果纳入下一次思考,形成“思考→执行→反馈→再思考”的迭代闭环-
七、底层原理/技术支撑点
核心技术栈
① 大语言模型推理(LLM Inference)
AI编程助手的基础能力来自LLM,模型在数十亿行代码和文档上训练而成
2026年主流的代码模型已具备千亿级参数规模,能够处理复杂的多步推理
② 上下文管理与记忆机制
AI编程助手的最大挑战之一是上下文窗口限制——LLM一次能“记住”的信息量有限,而一个完整项目动辄数千行代码。为此,现代Agent采用了多种解决方案:
上下文压缩(Compaction) :将早期对话中不关键的信息压缩为摘要,释放窗口空间-
滑动窗口:只保留最近的N轮对话,更早的内容自动丢弃
语义摘要:将非关键信息转化为高密度语义向量存储,需要时检索-
长期记忆:Claude Code的Auto Memory功能可以在多次会话间持续记录项目上下文-
③ 工具调用协议
Agent需要通过函数调用(Function Calling) 机制调用外部工具。例如:
文件系统操作(读取/写入/)
终端命令执行(运行测试、启动服务)
Git操作(提交、分支、合并)
网络请求(API调用、文档获取)
④ 多智能体协作
以中山三院发布的“睿麻助手”为例,该系统由21个专业智能体组成,包括集成、评估、监测、预警、决策等智能体,形成协同工作的智能生态系统-。在编程领域,Cursor 2.0可同时运行最多8个AI助手协同工作-。
💡 这些底层原理是面试中的高频考点,下一节会集中梳理。
八、高频面试题与参考答案
Q1:AI编程助手背后的核心技术是什么?
参考答案要点:
核心:大语言模型(LLM),负责理解和生成代码
增强:AI Agent架构,赋予模型工具调用和自主执行能力
支撑:上下文管理、检索增强生成(RAG)、函数调用等机制
一句话总结:LLM是大脑,Agent是身体,RAG是外部知识库
Q2:LLM和AI Agent有什么区别?面试如何答得清晰?
参考答案:
| 对比维度 | LLM | AI Agent |
|---|---|---|
| 能力边界 | 文本生成 | 规划+执行+反馈 |
| 是否可调用工具 | ❌ | ✅ |
| 是否有多步推理 | 有限 | ✅ |
| 典型示例 | 回答“这段代码做什么” | 执行“修复所有测试用例” |
答题金句:Agent = LLM + 规划能力 + 工具调用 + 记忆管理
Q3:AI编程助手的上下文管理是如何实现的?
参考答案:
滑动窗口:保留最近的N轮对话,丢弃早期内容
上下文压缩:将历史对话压缩为摘要,保留核心信息
语义检索:将历史信息向量化存储,需要时检索相关片段
长期记忆:跨会话持久化存储项目元信息(如构建命令、代码风格偏好)
Q4:传统IDE代码补全和AI编程助手(如Copilot)有什么本质区别?
| 维度 | 传统补全 | AI编程助手 |
|---|---|---|
| 技术基础 | 正则匹配/语法分析 | 大语言模型 |
| 上下文理解 | 当前文件局部 | 全项目+注释+历史对话 |
| 生成粒度 | 单词/单行 | 函数/类/整个模块 |
| 能否响应自然语言 | ❌ | ✅ |
Q5:多智能体(Multi-Agent)架构在AI编程助手中有什么价值?
参考答案:
将复杂任务拆解为子任务,由不同角色的Agent并行处理
例如:一个Agent负责代码生成,一个负责测试,一个负责代码审查
优势:提升效率、降低单Agent认知负载、易于分工协作
典型案例:Cursor 2.0的8 Agent并行编码-
九、结尾总结
核心知识点回顾
LLM是AI编程助手的大脑,负责理解和生成代码
Agent是LLM的“外挂身体” ,赋予工具调用和自主执行能力
上下文管理是Agent能够处理大型项目的关键技术
多智能体协作代表了AI编程助手的演进方向
易错点提醒
❌ 误以为LLM就是完整的AI Agent → ✅ Agent比LLM多了“做事”的能力
❌ 认为AI生成代码可以“一键到位” → ✅ 实际需要开发者审查和调整
❌ 忽略上下文窗口限制 → ✅ 大型项目需要合理拆分任务
下一篇预告
下一篇我们将深入AI编程助手的提示词工程(Prompt Engineering) ,从Zero-shot到Chain-of-Thought(思维链),教你如何写出让AI更“懂”你的高质量提示词,将AI编程助手的使用效率再提升一个台阶。