AI Agent(人工智能智能体)正在成为继大语言模型之后的又一个技术焦点。如果说2024年是LLM能力爆发的一年,那么2026年无疑是AI Agent从概念走向落地的关键之年。面对Agent这一新兴概念,许多技术学习者和从业者仍然存在这样的困惑:Agent和LLM到底是什么关系?记忆(Memory)、规划(Planning)、工具调用(Tool Use)这些能力是如何协同工作的?面试时被问到“Agent的核心架构”该从何说起?本文将围绕这些核心问题,从基础概念到原理剖析,从代码示例到面试考点,帮助读者在AI助手水獭所代表的Agent生态中建立起完整的技术认知体系。
本文共分为六个部分,分别覆盖:Agent是什么、传统方案的痛点、核心组件拆解、多智能体协作架构、实战代码演示、底层原理探源以及高频面试题解析,逐步递进、由浅入深。

一、痛点切入:为什么LLM还需要一个“Agent”
在深入Agent架构之前,先来看一个典型的应用场景——用户想要查询天气并发送邮件通知。

传统的大语言模型通常这样工作:用户输入Prompt,模型基于训练数据直接返回文本结果。如果要完成查询天气并发送邮件的复合任务,传统方案往往依赖开发者编写大量硬编码的胶水逻辑:
传统硬编码方案:耦合度高、扩展性差 def traditional_workflow(user_query): if "天气" in user_query: weather = call_weather_api("北京") return weather elif "邮件" in user_query: email = send_email("...") return email else: return llm.generate(user_query)
这种方案存在三个明显缺陷:
任务理解单一:无法处理“查询天气后再根据结果发邮件”这种复合意图
扩展性极差:每增加一个新能力都需要修改业务代码,无法动态组合
缺乏自主决策:模型没有“思考-执行-反思”的闭环能力
LLM虽然具备强大的文本生成能力,但它只是一个“说客”——能回答问题,却无法真正执行操作。这正是AI Agent诞生的根本原因:让LLM从被动的文本生成器转变为能够自主使用工具、执行任务的主动智能体。
正如2026年行业共识所概括的,智能体的核心公式为:
Agent = LLM + Planning + Memory + Tool Use-30
二、核心概念讲解:AI Agent(人工智能智能体)
2.1 标准定义
AI Agent(Artificial Intelligence Agent,人工智能智能体) 是指具备自主性(Autonomy)、反应性(Reactivity)、目标导向性(Goal-directedness)和社会性(Social Ability)的软件实体,能够感知环境、制定计划、调用工具执行动作,并在过程中进行自我纠错-47。
2.2 关键词拆解
自主性:Agent能够在没有人类实时干预的情况下独立运作
反应性:能根据环境变化实时调整行为
目标导向性:将模糊的用户意图拆解为可执行的子任务序列
社会性:能够与其他Agent或人类协作完成任务
2.3 生活化类比
可以把AI Agent理解为一个“全能助理”:
LLM = 助理的大脑,负责理解和生成语言
Planning(规划) = 助理的日程表,负责将大目标拆解为可执行步骤
Memory(记忆) = 助理的笔记本,记录历史对话和任务状态
Tool Use(工具使用) = 助理的双手,通过调用API、操作软件来完成具体动作
三、核心组件详解:Agent的四大支柱
3.1 Planning(规划)—— 目标拆解能力
Planning是Agent的“指挥中枢”,负责将复杂任务拆解为逻辑清晰的子任务序列。例如,用户提出“帮我分析季度财报并预警风险”,Agent的规划器会将其拆解为:① 读取财报文件 → ② 提取关键指标 → ③ 对比历史数据 → ④ 调用风险模型分析 → ⑤ 生成报告并发送-47。
3.2 Memory(记忆)—— 上下文管理
Agent的记忆分为短期记忆(对话历史)和长期记忆(向量数据库存储的领域知识)。结合RAG(Retrieval-Augmented Generation,检索增强生成)技术,Agent能够从企业知识库中检索相关信息,弥补LLM训练数据的时效性和私有数据访问的限制-24。
3.3 Tool Use(工具调用)—— 从“说客”到“创作者”
Tool Use是2026年Agent技术的最大突破,它让Agent能够自主调用外部API(如邮件、CRM、代码解释器),真正从“回答问题”转向“完成任务”-30。Tool Calling的本质是为LLM提供了I/O接口层,使其能够执行实际操作并访问实时数据-。
3.4 四者的逻辑关系
一句话概括:LLM是大脑,Planning是规划师,Memory是记事本,Tool Use是双手——四者协同,才能构成一个完整的智能体。
| 组件 | 角色类比 | 核心功能 |
|---|---|---|
| LLM | 大脑 | 语义理解、语言生成 |
| Planning | 规划师 | 任务拆解、流程编排 |
| Memory | 记事本 | 上下文存储、知识检索 |
| Tool Use | 双手 | API调用、外部操作 |
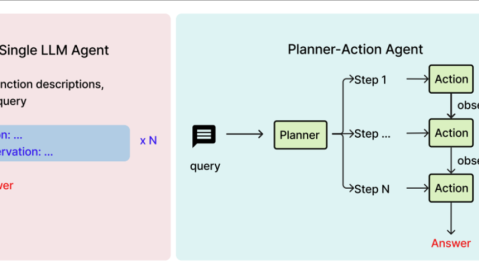
四、架构演进:从单体Agent到多智能体协作
4.1 单体Agent的局限
早期的AI Agent多为单体架构,即一个Agent独立完成所有任务。这种模式在复杂场景下面临三大挑战:任务拆解层级过深导致逻辑断裂、单一模型能力无法覆盖所有专业领域、单点故障会导致整个任务失败。
4.2 多智能体架构的兴起
2026年,行业正在从“单体Agent”向“多智能体协作”演进-30。典型的协作架构包含三类角色:
Manager Agent(管理者) :负责任务分配与调度
Worker Agent(执行者) :负责具体执行,如专家、绘图专家、代码专家等
Critic Agent(审核者) :负责合规性检查与结果验证
这种“数字工厂”模式极大提升了复杂任务的交付效率,同时通过组件解耦增强了系统的容错能力-8。2026年4月9日,Anthropic发布的Claude Managed Agents正是这一方向的重要实践——通过将会话(Session)、协调器(Harness)与沙盒(Sandbox)解耦,构建了具备高容错与安全性的底层架构-9。
五、代码示例:一个极简Agent的实现
以下是一个基于LLM构建的简易Agent实现,演示Planning → Tool Use → Memory的完整闭环:
极简Agent实现 - 展示核心工作流程 import json from typing import List, Dict class SimpleAgent: def __init__(self, llm_client, tool_registry: Dict): self.llm = llm_client LLM大脑 self.tools = tool_registry 工具注册表 self.memory = [] 记忆存储 self.max_iterations = 5 最大迭代次数 def plan(self, goal: str) -> List[str]: """Step 1: 任务规划 - 将目标拆解为步骤""" prompt = f"将任务'{goal}'拆解为3-5个逻辑步骤,每步格式为'step_x: 动作'" response = self.llm.generate(prompt) steps = [line.split(": ")[1] for line in response.split("\n") if "step_" in line] return steps def execute_step(self, step: str) -> str: """Step 2: 工具执行 - 判断需要调用哪个工具""" for tool_name, tool_func in self.tools.items(): if tool_name in step.lower(): return tool_func(step) 调用对应工具执行 return self.llm.generate(f"请根据步骤'{step}'直接回答") def run(self, goal: str) -> str: """Step 3: 主循环 - Plan → Act → Observe → Reflect""" steps = self.plan(goal) for i, step in enumerate(steps): 执行当前步骤 result = self.execute_step(step) 存入记忆 self.memory.append({"step": step, "result": result}) 反思检查:是否需要重新规划 if i < len(steps) - 1: reflection = self.llm.generate( f"已完成步骤'{step}',结果:{result}。是否可以继续下一步?" ) if "不可" in reflection: steps = self.plan(f"根据已完成结果{result},重新规划后续步骤") 最终汇总 final_response = self.llm.generate( f"用户目标:{goal}\n执行记录:{self.memory}\n请生成最终答案" ) return final_response 使用示例 tools = { "查询天气": lambda s: "北京天气:晴,25°C", "发送邮件": lambda s: "邮件发送成功" } agent = SimpleAgent(llm_client=my_llm, tool_registry=tools) result = agent.run("查询北京天气并将结果发送邮件通知团队")
关键代码解析:
plan():利用LLM将用户目标拆解为可执行步骤execute_step():根据步骤内容判断调用哪个外部工具run()中的反思检查:每次执行后验证结果,必要时重新规划
六、底层原理支撑:Agent技术栈依赖
AI Agent的实现依赖于以下底层技术:
Function Calling(函数调用) :LLM提供标准化的工具调用接口,使Agent能够结构化地请求调用外部API-
RAG(检索增强生成) :通过向量数据库实现语义检索,为Agent提供私有知识和实时信息-24
MCP(Model Context Protocol,模型上下文协议) :Anthropic于2024年底推出的标准化协议,旨在统一AI模型与外部工具的交互方式-41
Agent Loop(智能体循环) :经典的感知(Perceive)→ 规划(Plan)→ 执行(Act)→ 反思(Reflect)闭环
这些底层技术共同构成了Agent的能力底座,为上层应用提供了坚实的基础设施。
七、高频面试题与参考答案
Q1:Agent和LLM的根本区别是什么?
参考答案:LLM是被动的文本生成器,根据输入生成输出,不具备主动执行能力。Agent则在LLM基础上叠加了规划(Planning)、记忆(Memory)和工具调用(Tool Use)三大能力,能够自主分解任务、调用外部工具、并在执行过程中自我纠错。核心区别在于:LLM回答问题,Agent完成任务。
Q2:Agent = LLM + Planning + Memory + Tool Use,这四个组件是如何协同工作的?
参考答案:LLM提供语义理解和生成的基础能力;Planning负责将用户目标拆解为可执行的子任务序列;Memory(结合RAG)存储对话历史和外部知识,确保上下文连贯;Tool Use通过Function Calling机制调用API执行实际动作。四者形成“目标→拆解→检索→执行→反馈”的完整闭环。
Q3:RAG在Agent中扮演什么角色?
参考答案:RAG解决了两大核心问题:一是知识时效性,LLM训练数据有截止时间,而RAG可连接实时知识库;二是私有数据访问,企业数据无法进入模型训练,RAG通过向量检索实现安全调用。在Agent架构中,RAG通常作为Memory模块的核心实现方式,为规划与执行提供必要的上下文支撑-24。
Q4:如何避免Agent陷入无限循环或任务碎片化?
参考答案:① 设置最大迭代次数限制(如max_iterations=5);② 引入审计Agent进行结果验证,通过后及时退出循环;③ 避免过度拆解任务——过细的步骤会显著增加Token消耗和响应延迟,需要在逻辑精度与执行效率之间寻求平衡-30。
Q5:2026年Agent架构最重要的演进方向是什么?
参考答案:从单体Agent向多智能体协作架构演进,典型如“指挥官-专家”模式:指挥中枢负责任务拆解与调度,多个垂直领域的专家Agent负责具体执行,审计Agent负责合规检查。这种解耦设计提升了系统的容错能力和扩展性,2026年4月Anthropic发布的Claude Managed Agents即是这一方向的代表案例-9-46。
八、总结
本文系统梳理了AI Agent从核心概念到架构演进的完整知识链路,关键要点如下:
Agent的核心公式:Agent = LLM + Planning + Memory + Tool Use
四大组件分工明确:LLM是大脑,Planning是规划师,Memory是记事本,Tool Use是双手
架构演进方向:从单体Agent到多智能体协作,指挥中枢+专家Agent+审计Agent的“数字工厂”模式
底层技术依赖:Function Calling、RAG、MCP协议构成了Agent能力的技术底座
实践避坑:设置迭代上限,建立审计闭环,避免过度拆解
下一篇文章将深入探讨RAG检索增强生成的系统架构与实战优化技巧,敬请期待。