首段: 在全球招聘市场,企业平均每个岗位收到超过250份简历,大型企业核心岗位的简历量更可达千份以上-7。面对海量人才数据,传统人工筛选已难以应对,而AI简历助手的出现,正在从根本上改变这一局面。本文将系统拆解AI简历助手的核心技术原理,从实体提取、语义匹配到RAG检索增强生成,帮助读者建立从原理到落地的完整知识链路。
一、痛点切入:为什么需要AI简历助手?

传统招聘流程中,HR每天平均处理50+份简历,人工提取关键信息每份至少耗费30分钟-15。而传统ATS(Applicant Tracking System,应聘者追踪系统)仅依赖关键词匹配,容易被“关键词堆砌”的简历欺骗,也容易遗漏实际能力匹配但表达方式不同的优质候选人-7。
早期招聘系统的主要痛点包括:

耦合高:简历解析、岗位匹配、邮件通知等流程独立开发,缺乏统一工作流调度
扩展性差:新增一种简历格式或岗位类型需修改多处代码
效率低下:据统计,招聘流程中70%的时间浪费在无效简历筛选上-15
语义盲区:传统系统无法理解“负责Java后端开发”与“掌握Spring Boot框架”之间的语义关联-4
正是在这一背景下,AI简历助手应运而生,其核心目标是将招聘从“机械过滤”推向“智能理解”。
二、核心概念讲解:命名实体识别(NER)
定义: NER全称Named Entity Recognition(命名实体识别),指从非结构化文本中识别出预定义类别的实体,并将其分类到相应类别(如人名、机构名、地名、时间、数值等)的技术-。
关键词拆解:
“实体” :简历中具有明确语义的信息单元,如姓名、公司名、技能词
“识别” :通过模型判断文本中的哪些片段属于实体,以及属于哪类实体
生活化类比: 想象你是一位图书管理员,面前堆满杂乱无章的手写便签。你需要快速找出每张便签上的“人名”“书名”“日期”并分别放入不同文件夹。NER模型扮演的就是这个“智能图书管理员”——它会自动扫描简历文本,将“张三”标记为人名,“腾讯”标记为公司名,“Java”标记为技能。
核心价值: NER解决了AI简历助手的“读得懂”问题。它将原始文本转化为结构化数据,为后续匹配和评分提供基础数据支撑。当前主流NER方法主要依赖BERT、NLP、关键词模型等-,训练后的NER模型在简历解析场景中可达到92.4%的准确率和0.90的F1-score-。
三、关联概念讲解:大语言模型(LLM)
定义: LLM全称Large Language Model(大语言模型),指基于海量语料预训练的大规模神经网络模型,具备理解、生成、推理等通用语言能力。
与NER的关系: NER是“信息提取”的具体手段,而LLM是“语义理解”的通用能力底座。可以理解为:NER负责“找出简历里有哪些信息”,LLM负责“理解这些信息意味着什么”。
两者的差异对比:
| 维度 | NER | LLM |
|---|---|---|
| 输出类型 | 结构化实体(标签+位置) | 自然语言文本/推理结论 |
| 主要任务 | 提取、分类 | 生成、理解、推理 |
| 适用场景 | 技能提取、经验定位 | 匹配度评估、简历优化建议 |
| 依赖数据 | 标注数据集 | 海量无监督语料 |
简单示例:
NER处理:“5年Java开发经验” → 输出:
{技能: “Java”, 时长: “5年”, 类型: “工作经验”}LLM处理:结合岗位JD要求“资深后端工程师”,判断该候选人的5年Java经验与岗位匹配度,并生成具体优化建议
四、概念关系与区别总结
AI简历助手的技术架构呈现出清晰的“层次递进”逻辑:
一句话概括: NER是眼睛,负责“看懂”简历中的关键信息;LLM是大脑,负责“想明白”信息背后的含义和价值。
| 层级 | 技术 | 职责 | 类比 |
|---|---|---|---|
| 底层 | OCR + 格式解析 | 识别各类文档格式 | “打开书本” |
| 中层 | NER | 提取结构化实体 | “划出重点” |
| 高层 | LLM + RAG | 语义理解与匹配 | “理解含义并判断” |
这三层技术并非替代关系,而是协同关系——OCR负责“打开”,NER负责“标注”,LLM负责“理解”,共同完成简历智能筛选的完整闭环。
五、代码/流程示例演示
以下是AI简历助手的典型处理流程和代码示例:
核心处理流程:
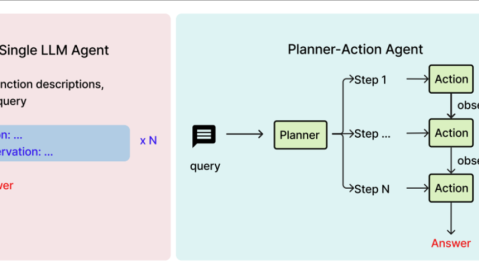
用户上传简历 → OCR/文本提取 → NER实体解析 → 向量化存储 → RAG检索 → LLM匹配评分 → 输出评估报告关键实现代码片段(基于Resume Matcher的NER核心逻辑):
实体提取核心逻辑(基于LlamaIndex + spaCy + GPT-4o) def extract_entities(resume_text): 1. 基础NLP解析 - 使用spaCy预训练模型完成初步实体标注 doc = nlp(resume_text) 2. 结构化prompt生成 - 定义招聘领域实体模板 prompt = StructuredResumePrompt().generate(doc.ents) 3. LLM精准提取 - 调用大模型对模糊实体进行上下文验证 return llm_provider.complete(prompt)
结构化输出模型(Pydantic):
class StructuredResumeModel(BaseModel): personal_data: PersonalData 姓名、联系方式、所在地 experiences: List[Experience] 公司、职位、工作时段 skills: List[Skill] 技术栈、证书、项目经验
参考来源:Resume Matcher采用混合式NER架构,通过spaCy完成基础标注,结合招聘领域实体模板进行领域适配,最后调用GPT-4o等LLM对模糊实体进行语义校正,确保提取结果准确可用-15。
执行流程解释: 当用户上传一份简历PDF后,系统首先通过OCR提取纯文本,NER模型扫描文本找出所有候选实体并分类,LLM对置信度较低的实体进行二次验证,最终输出符合标准模型的结构化数据,可直接用于下游匹配评分。
六、底层原理/技术支撑点
AI简历助手之所以能够实现智能解析,底层依赖三项核心技术:
1. 向量检索与嵌入(Embedding)
RAG(检索增强生成,Retrieval-Augmented Generation)的标准流程分为四步:用户提问 → 系统检索文档 → 拼接上下文 → LLM生成答案-31。其中核心是Embedding——将文档切块后转换为高维空间的坐标点,实现毫秒级的相似度检索。例如,Cohere的Rerank API(重排序接口)通过交叉编码器架构,将查询和文档拼接编码,准确捕捉两者的细粒度交互,使文档相关性评分准确率提升47%-31。
2. 大语言模型的推理与生成
LLM具备深度理解候选人的项目经历、能力图谱与成长轨迹的能力,而非简单匹配关键词-7。这使AI能对行业经验、技术栈等非直接匹配经验做泛化理解,人机一致性可达90%以上-5。
3. 多模态融合
2026年,AI简历筛选正从单一文本解析走向多模态评估。视频简历、作品集、代码仓库等多模态信息被整合进筛选流程,帮助企业构建更立体的人才画像。Gartner研究显示,采用多模态评估的企业,新员工留存率比仅依赖文本简历的企业高出28%-7。
七、高频面试题与参考答案
Q1:请简述AI简历助手的核心技术流程。
参考答案: AI简历助手通过三个核心环节实现智能筛选:(1)简历信息提取——结合OCR处理多格式文档,利用NER技术提取姓名、学历、技能等300+维度信息-4;(2)智能匹配——通过LLM进行语义级人岗匹配,非简单关键词比对;(3)RAG检索增强——在检索阶段快速召回候选,再由LLM重排序精筛。
Q2:NER和LLM在简历解析中各扮演什么角色?
参考答案: NER负责“信息提取”,将非结构化文本转化为结构化实体标签,输出技能、经验、教育等关键信息;LLM负责“语义理解”,评估实体间的深层关联和与岗位的匹配程度。两者分工协作:NER提供数据基础,LLM完成价值判断。
Q3:传统关键词匹配与2026年AI语义匹配的核心区别是什么?
参考答案: 传统方式依赖布尔逻辑和词频统计,易遗漏表达方式不同的候选人,也易被关键词堆砌欺骗;AI语义匹配基于大语言模型的深度理解能力,能识别“负责Java后端”与“掌握Spring Boot”的语义关联-4,据IDC预测,2026年超65%的企业招聘系统将采用语义级解析技术,误筛率预计降低40%以上-7。
Q4:RAG技术在AI简历筛选中的应用价值是什么?
参考答案: RAG通过“检索+生成”两阶段机制提升匹配精度。第一阶段用向量检索快速粗筛召回潜在候选(毫秒级响应),第二阶段用重排序模型对Top-K结果进行精筛,确保推荐理由可解释、可追溯-。这套机制将筛选从“看关键词”升级为“看实质能力”。
Q5:当前AI简历筛选面临的主要挑战有哪些?
参考答案: 主要包括三大挑战:(1)AI生成内容泛滥——约46%的求职者使用AI工具修改或生成简历内容-7,需引入真实性检测;(2)合规与偏见——欧盟《人工智能法案》已将招聘AI列为高风险类别,要求算法可解释性和审计追溯能力-7;(3)多模态融合——视频、作品集、代码仓库的异构数据整合仍需技术突破。
八、结尾总结
本文核心知识回顾:
| 知识点 | 关键结论 |
|---|---|
| NER | 实体识别是简历解析的“第一关”,将非结构化文本转化为结构化数据 |
| LLM | 提供语义理解能力,实现从“机械匹配”到“智能理解”的跨越 |
| RAG | 通过检索+重排序双阶段,提升匹配精度与可解释性 |
| 2026趋势 | 语义级解析成为主流,多模态评估、反欺诈、合规透明是三大方向 |
重点提示: 理解AI简历助手的关键在于把握“分层协同”架构——不是单一技术解决所有问题,而是NER、LLM、RAG各司其职、层层递进。在面试中,建议从“传统痛点→技术方案→底层原理→实际效果”的逻辑链展开回答,既体现深度又不失条理。
进阶预告: 下一篇将深入剖析AI Agent在招聘流程中的自主决策机制,包括多智能体协同、工具调用编排、以及如何构建从简历筛选到面试评估的完整自动化闭环,敬请期待。