深度解析AI助手Otter:语音转录技术原理与实战指南
一、开篇引入

在AI生产力工具飞速发展的今天,语音转文字已成为职场、学术和开发领域不可或缺的高频能力。许多技术学习者和开发者面临一个共同的痛点:会用Otter这类AI助手,却不懂它背后的工作原理;知道它能转录会议,却说不上来ASR和LLM到底如何协同;面试中被问到相关技术时,只能泛泛而谈“用了AI”。本文将带你从零到一,系统拆解AI助手Otter的技术架构、核心原理和实战应用,帮你建立完整的知识链路。
二、痛点切入:为什么需要AI助手Otter?

先来看一段传统手动记录会议内容的“伪代码”流程:
传统手动记录会议的方式 def manual_meeting_notes(audio_recording): 1. 反复听录音 2. 手动打字记录 3. 标记时间戳 4. 区分不同发言人 5. 手动整理会议摘要 return "数小时的重复劳动 + 遗漏关键信息"
这种方式的痛点:
效率极低:1小时会议,人工整理笔记可能需要2小时以上
准确性差:依赖记录者的注意力,容易遗漏重要信息
扩展性弱:多人协作时难以同步,无法快速检索历史会议内容
结构化困难:纯文本记录缺乏摘要、行动项等结构化信息
正是这些痛点,催生了AI助手Otter这样的自动语音转录和智能会议助手。其设计初衷很简单:让AI替人“听”和“记”,把人从重复劳动中解放出来。
三、核心概念讲解:ASR(自动语音识别)
概念定义:
英文全称:Automatic Speech Recognition
中文释义:自动语音识别,指将人类语音信号自动转换为文本的技术
拆解关键词:
“自动”:无需人工干预,系统自动完成语音→文字的转换
“语音识别”:识别和理解人类语音中的语义内容
生活化类比:
ASR就像一个“AI速记员”。你说话时,它一边听一边打字,实时将你说的话变成屏幕上的文字。不同的是,这个速记员永远不会累,也不会因为走神而漏记。
ASR的作用与价值:
ASR是AI助手Otter最底层的核心技术。没有ASR,Otter就无法“听懂”你在说什么。目前主流ASR系统采用端到端深度学习模型,结合上下文感知技术,在嘈杂环境下(如咖啡厅、户外)仍能保持高准确率-12。
ASR的标准工作流程:
音频采集 → 2. 预处理(降噪、分帧)→ 3. 声学特征提取 → 4. 声学模型识别 → 5. 语言模型解码 → 6. 输出文本
四、关联概念讲解:LLM(大语言模型)与AI摘要
概念定义:
英文全称:Large Language Model
中文释义:大语言模型,指基于海量文本数据训练的大规模神经网络模型,具备理解、生成和总结自然语言的能力
与ASR的关系:
ASR负责“听写”(语音→逐字稿),LLM负责“理解与加工”(逐字稿→摘要/行动项/问答)。二者串行协同,形成完整的智能转录链条。
| 对比维度 | ASR | LLM |
|---|---|---|
| 输入 | 音频信号 | 文本 |
| 输出 | 逐字文本 | 摘要/答案/结构化信息 |
| 核心能力 | 听写准确率 | 语义理解与生成 |
| 典型应用 | 实时转录 | AI摘要、AI Chat |
运行机制示例:
会议录音 → ASR识别 → “下周项目截止日期是4月15日,请各位提前完成” ↓ LLM分析 → “【行动项】4月15日前完成项目”
五、概念关系与区别总结
一句话概括:ASR是“耳朵”,LLM是“大脑”,AI助手Otter正是二者的有机结合体。
ASR:解决“说了什么字”的问题(语音→文本)
LLM:解决“说了什么意思”的问题(文本→结构化信息)
二者协同后的效果:AI助手Otter不仅能实时生成逐字稿,还能自动提炼会议摘要、提取行动项,甚至回答“上次会议定下的截止日期是什么时候”这样的具体问题-8。
六、代码/流程示例演示
6.1 通过Otter API获取转录结果(Python示例)
Otter提供REST API接口,支持开发者将转录能力集成到自己的应用中-11。
import requests 配置API密钥和请求URL url = "https://api.otter.ai/v1/transcriptions" headers = { "Authorization": "Bearer YOUR_API_KEY", 替换为你的API Key "Content-Type": "application/json" } data = { "audio_url": "https://example.com/meeting_audio.mp3", 音频文件URL "language": "en-US" 语言设置 } 步骤1:发送转录请求 response = requests.post(url, headers=headers, json=data) if response.status_code == 200: transcript_data = response.json() print(f"转录ID: {transcript_data['id']}") print(f"状态: {transcript_data['status']}") 步骤2:获取转录结果 result_url = f"{url}/{transcript_data['id']}" result = requests.get(result_url, headers=headers) print(f"转录文本: {result.json()['text']}") else: print(f"请求失败: {response.status_code}")
6.2 对比:传统方式 vs AI助手Otter
| 环节 | 传统人工方式 | AI助手Otter |
|---|---|---|
| 录音后处理 | 逐句手动打字 | 实时自动转写 |
| 发言人区分 | 手动标记“张总说”“李总说” | 声纹识别自动区分 |
| 会议摘要 | 人工提炼(耗时长) | AI自动生成 |
| 行动项提取 | 手动记录待办 | 自动识别并分配 |
| 内容检索 | 关键词困难 | Otter AI Chat自然语言问答 |
执行流程解读:
录制阶段:Otter通过麦克风采集音频
转录阶段:ASR引擎实时将语音转为文本,延迟<1秒,同时通过声纹识别自动区分发言人-12
摘要阶段:LLM分析逐字稿,自动输出Summary(段落式总结)、Outline(条列大纲)和Action Items(行动项)-27
交互阶段:用户可通过Otter AI Chat以自然语言提问,如“上次会议的截止日期是什么?”-27
七、底层原理与技术支撑
AI助手Otter的核心能力建立在以下几项底层技术之上:
1. 深度学习(Deep Learning)
Otter的ASR引擎基于深度神经网络(DNN),采用端到端深度学习模型,在嘈杂环境下仍能保持高准确率,英文场景准确率可达97%-12。
2. 声纹识别(Speaker Recognition)
通过分析每位发言人的声音特征(音调、音色、说话节奏),Otter能够在多人对话中自动区分不同发言人,准确率达到95%以上-12。
3. 上下文感知与语义理解
结合上下文感知技术,LLM能够理解对话的上下文关系,准确提炼关键信息和行动项。
4. 云原生架构
Otter基于云架构运行,支持实时转录、多端同步和无缝集成Zoom、Microsoft Teams、Google Meet等主流会议平台-。
💡 进阶提示:上述底层技术是面试中的高频考点。后续我们会出一篇专题文章,深入讲解深度学习中的Transformer架构及其在ASR系统中的应用,敬请关注。
八、高频面试题与参考答案
Q1:请简述AI助手Otter的ASR技术原理。
参考答案:
ASR(Automatic Speech Recognition)的核心流程包含三个关键模块:声学模型(将音频信号映射到音素)、发音词典(音素到单词的映射)和语言模型(单词序列的概率评估)。现代ASR系统采用端到端深度学习架构(如Conformer或Transformer),直接学习从音频特征到文本的映射关系。Otter在此基础上增加了声纹识别功能,能够区分不同发言人。
踩分点:声学模型 + 发音词典 + 语言模型 / 端到端架构 / 声纹识别
Q2:Otter如何处理多人会议中的发言人区分?
参考答案:
Otter通过声纹识别技术实现发言人区分。系统首先提取每位参会者的声音特征向量(包括音调、音色、共振峰等),然后在会议过程中实时匹配每个语音片段到最接近的特征向量,从而完成发言人的自动标记。这种技术即使在多人交叉发言的情况下也能保持较高的准确率(95%以上)。
踩分点:声纹识别 / 特征提取 / 实时匹配
Q3:AI助手Otter中ASR和LLM是如何协同工作的?
参考答案:
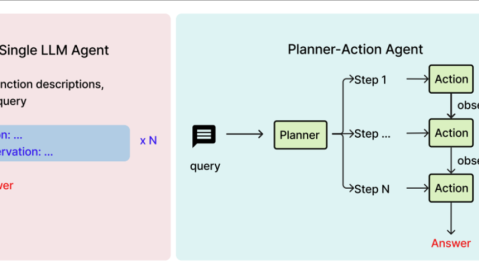
ASR和LLM形成串行协同的工作链路:
第一层(ASR) :负责语音→文本的转换,输出带有时间戳和发言人标记的逐字稿
第二层(LLM) :接收逐字稿作为输入,执行语义理解和生成任务,包括会议摘要、行动项提取、问答对话等
二者的分工清晰:ASR保证“听得准”,LLM保证“理解透”。
踩分点:串行协同 / 分工明确 / ASR负责转录 / LLM负责理解
Q4:Otter的实时转录延迟是如何控制的?
参考答案:
Otter采用流式ASR技术,不等待整段录音完成,而是在音频采集的同时进行分片处理和识别。具体技术包括:分块处理(将连续音频切分为短片段)、增量解码(每收到一个片段立即进行识别)、以及前缀缓存(保留已识别结果避免重复计算),从而实现<1秒的端到端延迟。
踩分点:流式ASR / 分块处理 / 增量解码
Q5:传统转录与AI助手Otter在工程实现上有什么区别?
参考答案:
传统方式:依赖人工听写,需重复播放录音、手动打字、标记时间戳和发言人,效率低下且容易出错
Otter方案:ASR自动完成转录,LLM自动生成摘要和行动项,支持实时协作和自然语言检索,准确率达95%以上
核心区别:从“人工处理”升级为“AI驱动自动化”,从“纯文本记录”升级为“结构化智能数据”。
踩分点:自动化 vs 人工 / 结构化 vs 纯文本 / 准确率对比
九、结尾总结
本文围绕AI助手Otter,系统梳理了以下核心知识:
✅ ASR(自动语音识别):将语音→文本,Otter的“耳朵”
✅ LLM(大语言模型):将文本→结构化信息,Otter的“大脑”
✅ 二者关系:串行协同,分工明确
✅ 代码示例:Otter API调用和传统方式对比
✅ 底层支撑:深度学习、声纹识别、云架构
✅ 面试要点:ASR三模块、发言人区分、流式转录
重点提示:
⚠️ 不要混淆“AI助手Otter”与同名多模态研究模型“Otter”
⚠️ API集成时注意异步轮询机制和语言参数的格式(小写)
⚠️ 面试中回答ASR原理时,务必涵盖声学模型、语言模型、解码器三要素
下一篇预告:我们将深入ASR技术的底层——Transformer架构详解,拆解自注意力机制如何在语音识别中发挥作用,敬请期待!
📌 参考文献:
Otter.ai官方文档与产品介绍-8
三款高效语音转文字软件深度评测-12
高效转写必备!6款视频语音转文字软件深度测评-11
Otter.ai使用教程与功能详解-27
Otter.ai企业级功能与集成方案-