政策AI助手核心技术科普:RAG+LLM从零到一(2026年4月)(29字)
你是否曾被政策条文看得头晕眼花,或在面试中被问到“政策AI助手是怎么工作的”而当场卡壳?近年来,“政策AI助手”这类基于大语言模型与检索增强生成的智能系统,正迅速成为政务服务、企业服务等领域的高频技术组件-54。但很多开发者和学习者对它的理解仍停留在“会聊天的机器人”层面,一旦被追问“它背后怎么检索知识、怎么生成答案、底层依赖什么技术”,就容易答不上来。本文将围绕政策AI助手的技术本质,从痛点出发,拆解RAG与LLM的概念、关系、代码示例、底层原理和面试考点,帮你建立从“知道”到“懂得”的完整知识链路。
一、痛点切入:为什么需要政策AI助手?
在过去,企业和个人想了解一项政策,通常只能靠两种方式:要么在政府网站上逐篇翻阅红头文件,要么拨打咨询热线排队等待人工解答。这种传统模式存在三大硬伤:

效率低下:政策文件动辄数十页,人工检索一篇可能耗时数十分钟。某政务平台原本需要数月才能梳理完上千份政策文件,人力成本极高-35。
信息滞后:政策更新频繁,传统知识库更新周期长,用户往往查到的是过时信息-54。
解答不精准:人工咨询受限于个人知识储备,关键词又无法理解用户真实意图——“集成电路企业能享受什么补贴”这类自然语言问法,传统系统根本听不懂-54。
政务大模型的应用数据显示,传统人工服务模式之下,政务热线座席日均接件压力巨大,政策触达的“最后一公里”问题长期存在-54-72。
正是在这样的背景下,政策AI助手应运而生——它要做的,就是让机器像专业的政策顾问一样,既能“听得懂”自然语言提问,又能“查得准”海量政策条文。
二、核心概念讲解:RAG(检索增强生成)
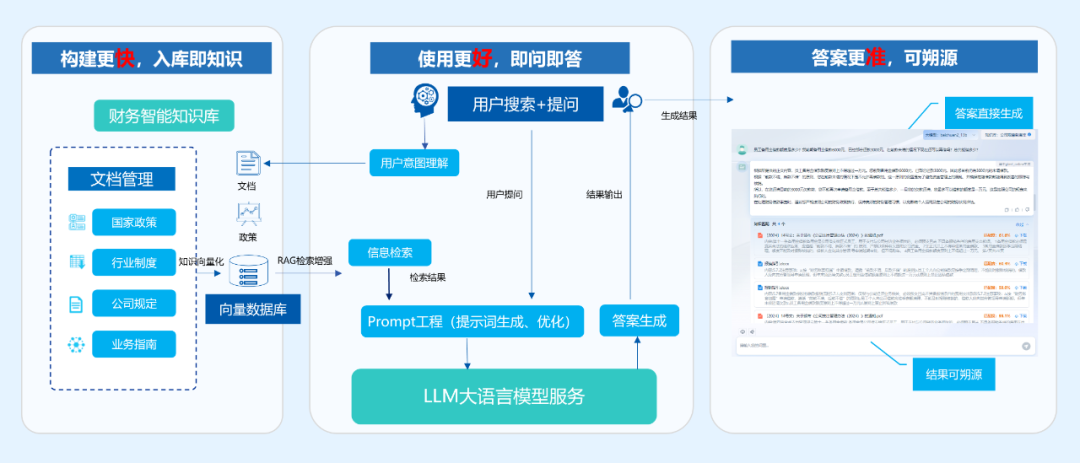
定义:RAG,全称Retrieval-Augmented Generation(检索增强生成),是一种结合“外部知识检索”与“大语言模型生成”的混合架构。它先从知识库中检索相关文档,再让模型基于这些检索结果生成答案-52。
通俗类比:如果把传统大模型比作一个“死记硬背”的考生——考试时只能凭记忆作答,记不住的就乱编;那么RAG就像是给这个考生配了一个“开卷考场”——遇到问题可以先翻书查资料,查到了再组织语言作答。这样一来,答案既有权威依据,又有人性化的表达。
核心价值:RAG解决了大模型的三大痛点——知识滞后(训练数据有时间截止)、领域局限(对垂直行业知识覆盖不足)、幻觉频发(编造看似合理实则错误的内容)-13。简单来说,它让AI从“凭记忆答题”变成“查资料后严谨作答”-13。
三、关联概念讲解:LLM(大语言模型)
定义:LLM,全称Large Language Model(大语言模型),是一种基于海量文本数据训练而成的深度学习模型,具备自然语言理解与生成能力。典型代表包括DeepSeek、GLM、Qwen等。
在政策AI助手中的角色:RAG负责“查资料”,LLM则负责“读资料+写答案”。在政策AI助手的标准架构中,LLM通常作为核心引擎,配合RAG技术从政策知识库中检索信息后生成专业回答-54。例如,上海联通临港“政策AI”助手,正是以DeepSeek大语言模型为技术核心,结合专属政策知识库,实现了多轮对话和精准政策匹配-54。
四、概念关系与区别总结
RAG与LLM的关系,可以用一句话概括:RAG是检索架构,LLM是生成引擎;RAG解决“查什么”,LLM解决“怎么说”。
| 维度 | LLM | RAG |
|---|---|---|
| 本质 | 生成模型 | 检索+生成的架构模式 |
| 知识来源 | 模型内部参数(训练数据) | 外部知识库(实时检索) |
| 更新成本 | 高(需重新训练) | 低(只需更新知识库) |
| 优势 | 语言表达自然、推理流畅 | 回答准确、可溯源、实时性强 |
二者是“互补协作”的关系,而非“谁替代谁”。在实际的政策AI助手中,二者缺一不可:没有LLM,RAG检索到的资料只是一堆文字堆砌;没有RAG,LLM面对专业政策问题就容易“胡说八道”。
五、代码/流程示例演示
下面我们用Python伪代码演示一个极简的政策AI助手核心流程。本示例基于RAG架构,展示从用户提问到生成答案的完整链路:
政策AI助手核心流程示例(伪代码,基于RAG架构) 依赖:向量数据库(如Chroma/Milvus)、LLM(如DeepSeek/Qwen) def policy_ai_assistant(user_query): 步骤1:将用户问题向量化 query_embedding = embed_model.encode(user_query) 步骤2:从政策知识库中检索相关片段 采用多通道召回策略(语义检索 + 关键词检索) semantic_results = vector_db.similarity_search(query_embedding, k=5) keyword_results = bm25_index.search(user_query, k=3) retrieved_docs = merge_and_rerank(semantic_results, keyword_results) 步骤3:构建Prompt,注入检索结果作为上下文 prompt = f""" 你是一位专业的政策解读助手,请基于以下政策资料回答问题。 如果资料中没有相关信息,请如实告知,不要编造。 【参考资料】 {format_docs(retrieved_docs)} 【用户问题】 {user_query} 【回答】 """ 步骤4:调用LLM生成最终答案 answer = llm.generate(prompt, max_tokens=500, temperature=0.3) return { "answer": answer, "sources": [doc.source for doc in retrieved_docs] 提供溯源 } 调用示例 result = policy_ai_assistant("我们是一家集成电路企业,在临港可以享受哪些优惠政策?") print(result["answer"]) print("信息来源:", result["sources"])
执行流程解释:
嵌入编码:将用户自然语言问题转换为向量(语义特征表示)。
混合检索:同时进行语义向量检索(找意思相近的内容)和BM25关键词检索(找字面匹配的内容),再经重排序合并,确保召回全面-10。
Prompt组装:将检索到的政策片段作为“参考资料”注入提示词。
LLM生成:模型基于参考资料生成符合人类习惯的答案,避免幻觉。
一个实际的低代码案例参考:在华为云AI Agent平台搭建“常州小智”政策助手时,开发者只需上传政策文档创建知识库(选择VectorRAG类型),再配置DeepSeek模型和工作流,即可完成一个可用的政策问答智能体-31。
六、底层原理/技术支撑点
政策AI助手的底层技术栈,主要依赖以下三大支撑:
1. 向量化嵌入(Embedding)
政策文本需要先“翻译”成计算机能理解的数学向量。Embedding模型将每个文本块映射到高维语义空间中,语义相似的文本在向量空间中的距离更近-13。
2. 向量数据库与混合检索
存储政策知识库的向量数据需要专用数据库(如Milvus、Chroma)。为提升检索准确率,业界普遍采用“混合检索”策略:向量做语义匹配,BM25算法做关键词匹配,再用重排序模型(Rerank)合并结果。采用这种混合检索模式的企业,知识检索准确率平均提升了约25%-14。
3. 多轮对话与上下文管理
真正的政策咨询往往是多轮交互的,例如用户先问“集成电路有哪些补贴”,再追问“申请门槛是什么”。这要求系统能维护对话历史,并在每次检索时结合上下文意图。POLRAG框架在社保、就业补贴等政策场景测试中,正是通过引入历史对话上下文和检索结果共同构建Prompt,显著提升了回答准确率-10。
注:以上仅做原理层面的定位与铺垫。深入源码级的实现(如Transformer注意力机制、微调策略等),我们将在后续进阶文章中详细展开。
七、高频面试题与参考答案
以下是面试中关于政策AI助手/RAG方向的高频考题,附简洁规范答案:
Q1:什么是RAG?它解决了什么问题?
答案:RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合“外部知识检索”和“大语言模型生成”的混合架构。它解决了传统大模型的两个核心痛点:一是“知识滞后”,大模型训练数据有时间截止;二是“幻觉问题”,大模型可能编造不存在的信息。RAG让模型先检索再生成,既保留了LLM的生成能力,又赋予它“实时学习”和“精准引用”的特性-52。
Q2:RAG和SFT(监督微调)有什么区别?分别适用什么场景?
答案:SFT是在模型内部“灌知识”,通过训练让模型记住特定领域数据;RAG是让模型“查资料”,从外部知识库实时检索。RAG的优势是知识更新快、灵活、成本低;SFT的优势是推理更自然、响应更快。适用场景:实时信息查询、知识频繁更新的场景选RAG;需要模型风格统一、响应速度优先的场景选SFT-52。
Q3:如何解决RAG中的“检索不准”问题?
答案:检索不准通常由三种原因造成:切片策略不合理、召回算法单一、相似度阈值设置不当。解决思路:①采用混合检索(向量检索+BM25关键词检索)提升召回率;②引入重排序模型(Reranker)对初筛结果二次打分;③根据业务场景优化分块策略(Chunking),平衡精度与上下文完整性-52。
Q4:政策AI助手中如何确保答案的权威性和可追溯性?
答案:关键在于两点:一是建立高质量的专属政策知识库,对政策文件进行结构化清洗和标注;二是在生成答案时携带溯源信息,即告诉用户答案引用了哪份政策文件的哪一具体条款。政务场景中还需配合权限分级和操作审计机制,确保可追溯、可问责-1。
Q5:大模型“幻觉”的成因是什么?RAG如何降低幻觉?
答案:大模型幻觉的根本原因是LLM基于概率生成而非基于事实检索——当遇到知识盲区时,模型会“编造”看似合理实则错误的内容。RAG降低幻觉的核心机制是“用外部检索结果约束生成过程”:LLM被要求严格基于检索到的参考资料作答,而非依赖自身的参数化记忆。如果检索结果中不包含相关信息,应如实告知用户“未找到相关资料”,从而从源头阻断幻觉-52。
八、结尾总结
本文围绕政策AI助手这一技术主题,按“问题→概念→关系→示例→原理→考点”的链路,系统梳理了以下核心内容:
为什么需要它:传统政策咨询服务存在效率低、信息滞后、解答不准三大痛点
RAG:检索增强生成,让AI“查资料后作答”,解决幻觉与知识滞后
LLM:大语言模型,作为政策AI的“生成引擎”,负责理解问题、组织答案
二者关系:RAG是架构、LLM是引擎,协作互补、缺一不可
核心底层:Embedding、向量数据库、混合检索、多轮对话管理
面试高频考点:RAG定义、与SFT的区别、检索优化方案、幻觉成因与应对
重点记忆一句话:政策AI助手 = RAG(检索架构)+ LLM(生成引擎)+ 高质量政策知识库。
关于本主题的进阶内容——如GraphRAG知识图谱增强、本地化私有部署方案、大模型微调与RAG的混合策略等——我们将在后续系列文章中深入讲解,欢迎持续关注。
下一篇预告:政策AI助手的本地化私有部署方案:从百亿级模型到边缘端推理实战